
Synthesising mixed data to reach defensible evaluative conclusions
As evaluators, we try our best to make sense of different types of data to establish evaluative conclusions about program effectiveness. However, when measuring a program’s impact, this can be challenging if your qualitative and quantitative data sources are telling differing stories.
This raises the question about how to make judgments about a program’s impact if the data is pulling us in two different directions.
In this blog, we explore the synthesis-of-findings method (McConney, Rudd, & Ayres, 2002) which is one way to make sense of divergence in the data when trying to understand the overall or summative impact of a program.
When is the Mixed Method Synthesis approach useful?
The synthesis-of-findings approach is useful for conducting mixed method evaluations to understand summative program outcomes. It is also useful to help understand and address divergent findings across different data sources in a systematic and transparent manner. As effectiveness is calculated systematically and allows data sources to be compared on a common scale, findings have a defensible basis.
This blog steps through the method, and then an applied example.
Know what the goals of the program are
Before applying this method, we need to understand the program’s goals.
For example, if we have a school program focussed on wellbeing services for students after an environmental disaster, one goal of the program might be to see a reduction in children’s anxiety at the end of the program. Another might be that students are able to focus on their learning, measured by academic achievement. Then we use the synthesis-of findings method to support integration of qualitative and quantitative evidence for each goal.
So how do we apply the method?
The synthesis-of findings method consists of four key steps, covered in more detail below, but summarised as:
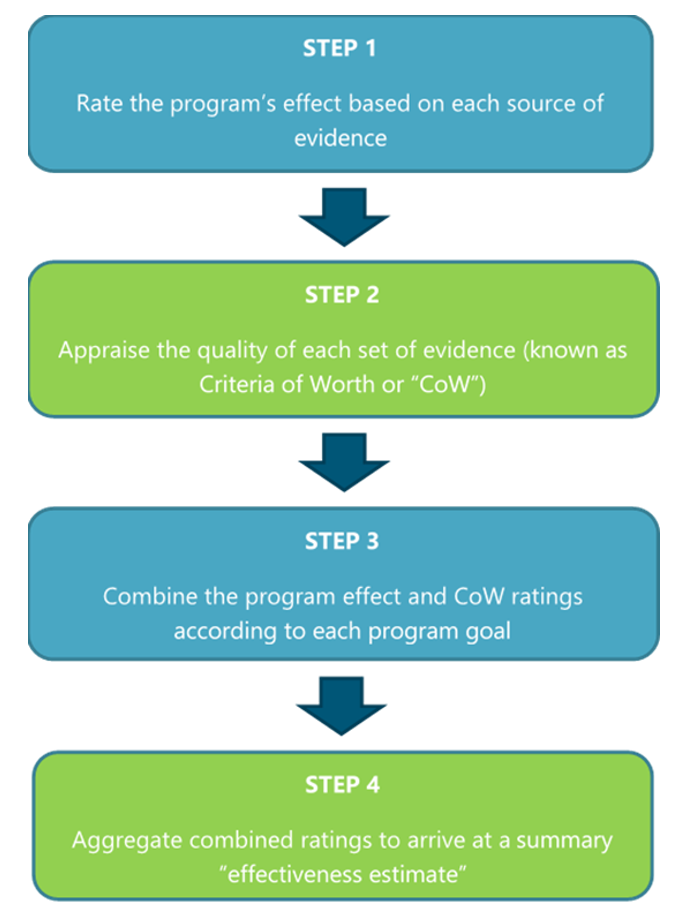
Step 1: Rate the program’s effect based on each source of evidence
For Step 1 we use a matrix like the one below, with each data source used to measure a program’s effect on a specific goal, added to the first column. Qualitative data sources could include interviews and focus groups while quantitative data sources could include surveys and assessment data.
The top row provides us with a ratings scale to note what each of our data sources has concluded about program outcomes, whether positive or negative, and to what degree. Usually, the evaluation team will work with key stakeholders to analyse each source to assess the direction and magnitude of a program’s effect.

Step 2: Rate each data source based on agreed Criteria of Worth (“CoW”)
Then we fill in a similar matrix for Criteria of Worth, however this one requires judgement on how valuable each respective data source is in answering questions about program impact.
In this step, evaluators should work together with key stakeholders to reach a consensus on the criteria that will be used to determine the worth of each data source. This can assist in achieving mutually agreed upon criteria that everyone understands and accepts. Examples of criteria that can be used when developing “CoW” include the following:
Accuracy – Does your data actually measure what it claims to measure?
Reliability – Has your data been gathered using instruments that provide consistent results across time, or consistency across people using the instrument?
Relevance – How well aligned and important is your data in answering the evaluation questions?
Representative – To what extent does the scope of your data source match the population of participants in the program?

Step 3: Combine program effect and CoW ratings
After rating each data source against the CoW, the ratings for program effectiveness and CoW can be aggregated. The equation that is formed provides an estimate of program effectiveness for a particular outcome/ goal based on summing the product of the worth of and effectiveness of each data source, outlined below.

Source: McConney, A., Rudd, A., & Ayres, R. (2002). Getting to the bottom line: A method for synthesizing findings within mixed-method program evaluations. American Journal of Evaluation, 23(2), 121-140.
Aggregate Combined Ratings
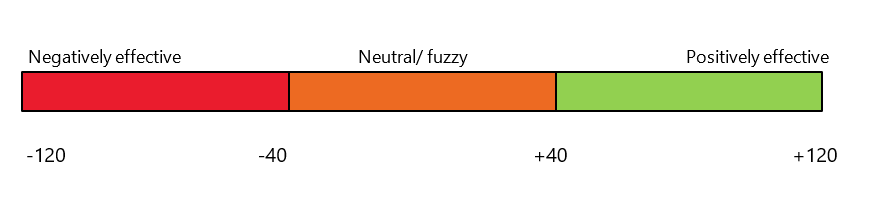
This process results in a score for the program by each outcome on a closed effectiveness scale. The end-points of the scale are determined by the number of data sources and number of CoW used in assessing the quality of the data. In Step 1 above, each data set has an effect rating ranging from -2 (large negative effect) to +2 (large positive effect) and there are four CoW, each of which can vary from +1 (low) to +3 (high).
For each data set the CoW rating could range from a low of 4 (i.e., 4 x 1; poor worth data) to a high of 12 (i.e., 4 x 3; high worth data). So, the combination of the ‘effect rating’ (+/-2) and ‘CoW rating’ (+/-12) could vary from a low of -24 to a high of +24. Summed over the five data sets there is a possible effectiveness estimate ranging from a low of -120 (negative effects, worthy data) to a high of +120 (positive effects, worthy data).
These steps are repeated for each program goal under evaluation and an average is then taken to calculate an overall program wide effectiveness score.
Applying in the Real World
So how would we apply this to our post-disaster school wellbeing program? Goal by goal, we fill in the program effect and Criteria of Worth tables. We’ll start with the reducing anxiety goal.

The evaluators work with teachers and principals to reach a consensus on what criteria we will use to determine the worth of each data source. We work through divergence in opinion through stakeholder meetings, until we have criteria of worth everyone accepts.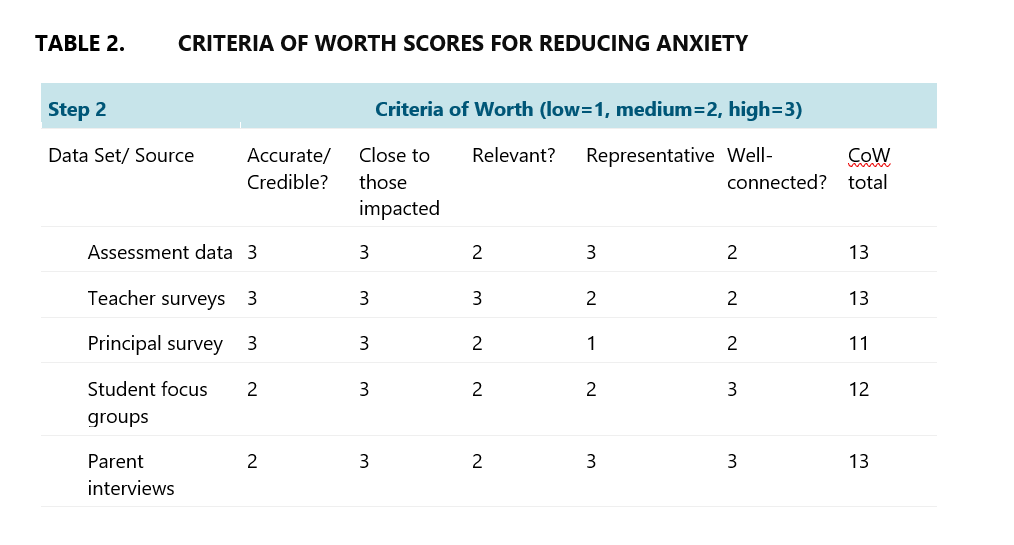
A score is calculated using data from both tables, outlined in the equation below.
Y reduced anxiety =0*13+1*13+1*11+1*12+2*13=62
This result is then interpreted by adding to the scale.
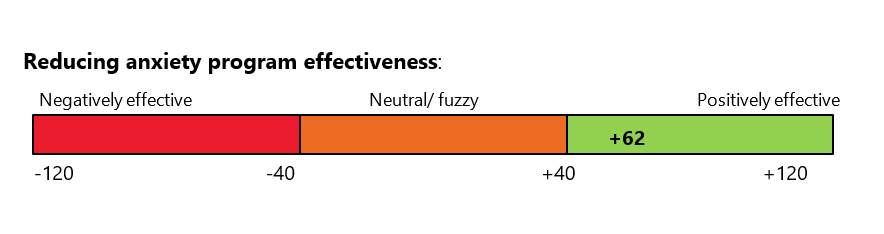
For reducing anxiety, after synthesising results from the different evidence sources, the program had a positive effect on this goal.
The step above is then repeated for the academic achievement goal.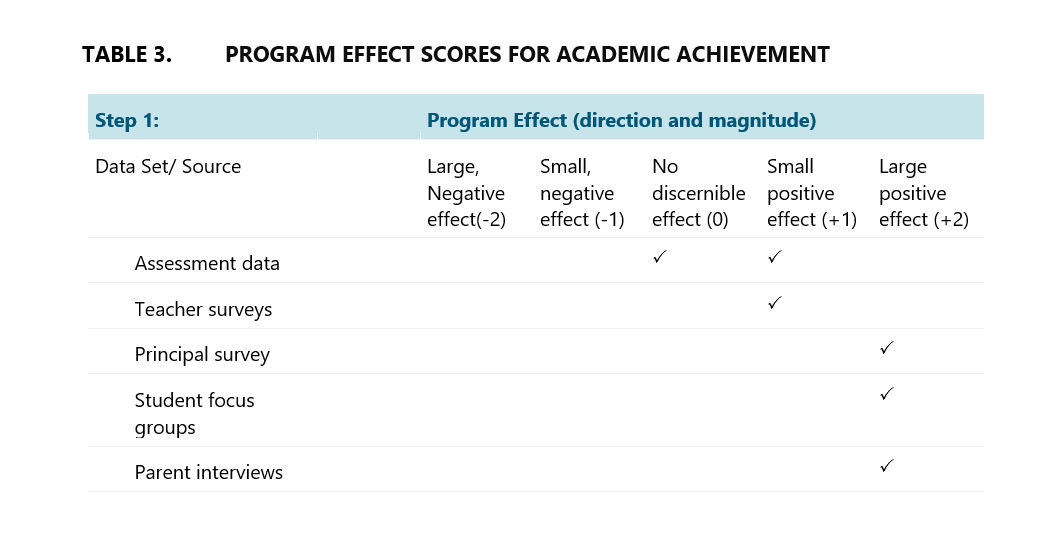
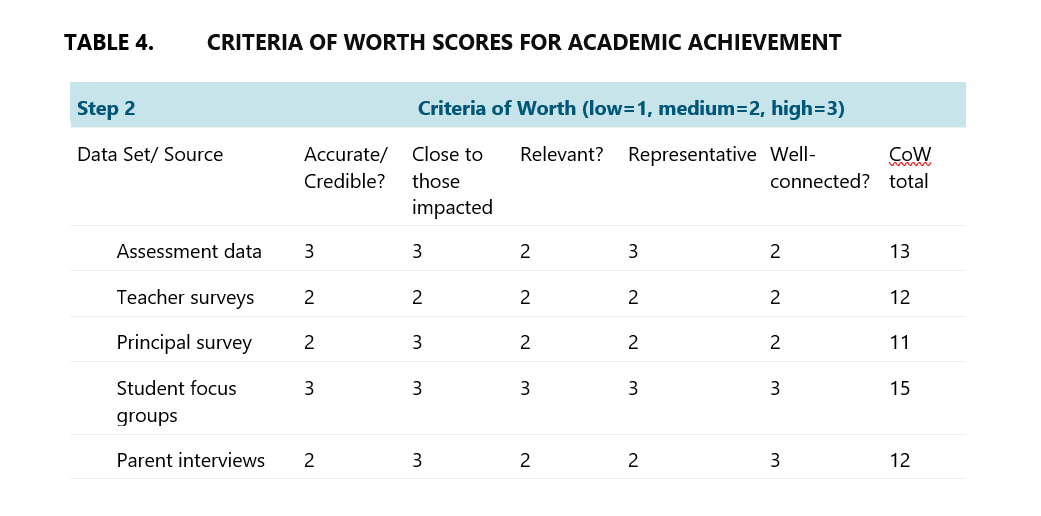
A score is calculated using data from both tables, outlined in the equation below.
Y academic achievement=0*13+1*12+2*11+2*15+2*12=88
The next step is to take an average across the two goals, to calculate an overall program wide effectiveness score.
[Y academic achievement + Y children anxiety]/2 = [62 + 88]/2 =75
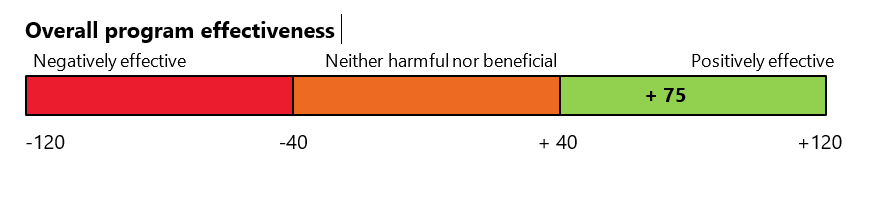 This means that overall, synthesising scores across program goals, the program was positively effective.
This means that overall, synthesising scores across program goals, the program was positively effective.
Factor in fidelity of implementation
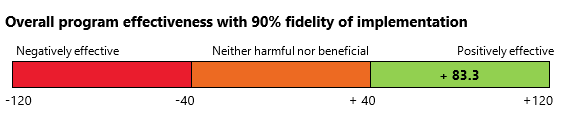
To more accurately capture a program’s effectiveness, including fidelity of program implementation can sometimes be helpful (this refers to whether the program is being implemented as planned). This can help evaluators understand to what extent fidelity is impacting on the outcome seen. If, for example, a program is being implemented at about 90% of its ideal version, we can then divide the overall program score by 0.9 to reflect this (McConney, Rudd, & Ayres, 2002). This tells us that our program would have a positive effect of 83.3 if it was implemented at 100% fidelity.
Final Thoughts
This method is just one of a range of techniques for addressing a recurring challenge in mixed method evaluations, where evidence sources are varied and paint a different account of the effectiveness of a program.
At ARTD, we have found the synthesis-of findings method provides a flexible and participatory technique for reaching defensible evaluative conclusions. It is particularly useful for results synthesis when the evidence does not ‘converge’ and there are concerns about placing too much weight on particular forms of data (e.g., privileging academic test scores).
If there are other mixed method approaches out there for synthesising and integrating data, this a clarion call to discuss these as part of our series. Demystifying mixed methods will allow us to understand, appreciate and apply synthesis techniques more in our work to help develop stronger, more meaningful evaluations.
References
McConney, A., Rudd, A., & Ayres, R. (2002). Getting to the bottom line: A method for synthesizing findings within mixed-method program evaluations. American Journal of Evaluation, 23(2), 121-140.



